Web Scraper插件下载 Web Scraper Chrome插件(网页爬虫插件) v1.29.60 免费安装版
Web Scraper Chrome插件是一款网站数据提取工具,知识兔可以帮助不懂代码的用户实现数据爬取功能。使用此扩展,您可以创建一个sitemap(站点地图),包含该如何遍历网站以及应提取哪些内容等。使用这些sitemap,Web Scraper将相应地导航站点并提取所有数据。稍后,知识兔可以将已筛选的数据导出为CSV。感兴趣的朋友快来下载体验吧。
功能介绍
1. 刮开多页
2. 废除的数据存储在本地存储中
3. 多种数据选择类型
4. 从动态页面中提取数据(JavaScript+AJAX)。
5. 浏览刮取的数据
6. 6.知识兔将剪报的数据导出为CSV
7. 导入、导出网站地图
8. 仅取决于Chrome浏览器
软件特色
指点和知识兔点击界面
知识兔的目标是让网页数据提取尽可能简单。通过简单的指向和知识兔点击元素来配置刮刀。不需要编码。
从动态 网站中提取数据
Web Scraper可以从多级导航的网站中提取数据。它可以在所有级别上导航一个网站。
分类和子分类
分页
产品页面
从动态 网站中提取数据
为现代网络设计
现在的网站都是建立在JavaScript框架之上的,这些框架使得用户界面更容易使用,但对刮刮客来说却不太容易。Web Scraper解决了这个问题。
完全的JavaScript执行
等待Ajax请求
分页处理程序
页面向下滚动
为现代网络而建
模块化选择器系统
Web Scraper允许您从不同类型的选择器中建立网站地图。该系统可以根据不同的站点结构来定制数据提取。
模块化选择器系统
以CSV、XLSX和JSON格式导出数据
构建搜刮器,搜刮网站,并直接从浏览器导出CSV格式的数据。使用Web Scraper Cloud以CSV、XLSX和JSON格式导出数据,通过API、webhooks访问,或者通过Dropbox导出数据。
插件安装说明
1、在打开的谷歌浏览器的扩展管理器
就是知识兔点击最左侧的三个点,在弹出的菜单中选择【更多工具】——【扩展程序】
或者你可以在地址栏中直接输入chrome://extensions/
2、进入扩展程序页面后将开发者模式打勾
3、最后将解压出来的crx文件拖入到浏览器中即可安装添加
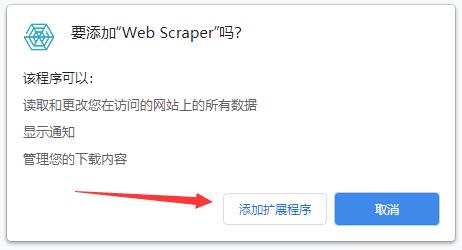
4、如果知识兔出现无法添加到个人目录中的情况,知识兔可以将crx文件右键,然后知识兔选择【管理员取得所有权】,再尝试重新安装
5、安装好后即可使用
下载仅供下载体验和测试学习,不得商用和正当使用。